- Ubuntu Linux 14.04
- MongoDB 2.6.6 [installation how-to]
- Oracle JDK 7 [installation how-to]
- Maven 3.2.3 [installation how-to]
- Eclipse Luna 4.4.1 [installation how-to]
- Spring JPA 4.1.4
- Spring Data for MongoDB 1.6.1
Introduction
Spring Data for MongoDB is part of the umbrella Spring Data project which aims to provide a familiar and consistent Spring-based programming model for for new datastores while retaining store-specific features and capabilities.Rationale
I started to use Spring Data for MongoDB because the default query API in Mongo was awkward for Java.
For example, searching for
i > 50 is represented as:
cursor = coll.find(new BasicDBObject("i", new BasicDBObject("$gt", 50)));
The equivalent Spring enabled query is:
query(where("i").gte("50"))
While these are both simple cases, the former case is both syntactically and semantically awkward. Semantically, we lose a lot of meaning as the query grows in length. For queries with multiple conditions, a large number of BasicDBObject instances have to be created and appended to simulate a pipeline. Syntactically, operators like ">" and "<" have to be escaped.
In the latter case, the Java pipeline looks somewhat more like a Javascript document string. While using MongoDB in Java may never have the syntactic elegance of Javascript (native JSON), Spring brings us closer to this.
Spring support brings further advantages around deployment, integration and environment support for MongoDB in enterprise applications.
Test Cases
I use this test case to demonstrate CRUD functionality over a working MongoDB connection. This test case is also helpful as a quick reminder of the Spring syntax for MongoDB as I prefer working with python or in the javascript shell directly.
MongoSpringCrudTest.java:
package org.swtk.sandbox.mongodb.spring; import static org.junit.Assert.assertEquals; import static org.junit.Assert.assertNotNull; import static org.junit.Assert.assertNull; import static org.junit.Assert.assertTrue; import static org.springframework.data.mongodb.core.query.Criteria.where; import static org.springframework.data.mongodb.core.query.Query.query; import static org.springframework.data.mongodb.core.query.Update.update; import java.util.List; import org.apache.commons.logging.Log; import org.apache.commons.logging.LogFactory; import org.junit.Test; import org.springframework.data.mongodb.core.MongoOperations; import org.springframework.data.mongodb.core.MongoTemplate; import org.swtk.sandbox.mongodb.spring.dto.Person; import com.mongodb.Mongo; public class MongoSpringCrudTest { private static final Log log = LogFactory.getLog(MongoSpringCrudTest.class); @Test public void run() throws Throwable { @SuppressWarnings("deprecation") MongoOperations mongoOps = new MongoTemplate(new Mongo(), "database"); Person p = new Person("Joe", 34); /* insert is used to initially store the object into the database. */ mongoOps.insert(p); /* find */ p = mongoOps.findById(p.getId(), Person.class); assertNotNull(p); /* update */ mongoOps.updateFirst(query(where("name").is("Joe")), update("age", 35), Person.class); log.info("Updated: " + p); /* test the update */ p = mongoOps.findOne(query(where("name").is("Joe")), Person.class); assertNotNull(p); assertEquals(35, p.getAge()); /* delete */ mongoOps.remove(p); assertNull(mongoOps.findOne(query(where("i").gte("50")), Person.class)); /* check that deletion worked */ /* find one ... */ assertNull(mongoOps.findOne(query(where("name").is("Joe")), Person.class)); /* find all ... */ List<Person> people = mongoOps.findAll(Person.class); assertNotNull(people); assertTrue(people.isEmpty()); mongoOps.dropCollection(Person.class); } }
Person.java (domain transfer object):
package org.swtk.sandbox.mongodb.spring.dto; public class Person { private String id; private String name; private int age; public Person(String name, int age) { this.name = name; this.age = age; } public String getId() { return id; } public String getName() { return name; } public int getAge() { return age; } @Override public String toString() { return "Person [id=" + id + ", name=" + name + ", age=" + age + "]"; } }
The Soundex Use Case
The Soundex algorithm is in the class of approximate string matching (asm) algorithms.
The goal is for homophones (e.g. Jon Smith, John Smythe) to be encoded to the same representation so that they can be matched despite minor differences in spelling.
package com.mycompany; public class SoundexResult { private String encoding; private String id; private String value; public String getEncoding() { return encoding; } public String getId() { return id; } public String getValue() { return value; } public void setEncoding(String encoding) { this.encoding = encoding; } public void setId(String id) { this.id = id; } public void setValue(String value) { this.value = value; } }
The soundex encoder is provided through an apache-commons codec:
<dependency> <groupId>commons-codec</groupId> <artifactId>commons-codec</artifactId> <version>1.9</version> </dependency>
Since this Soundex algorithm is designed for English phonology only, a simple check for each String that it exists within the English alphabet, then a call out to the codec:
new org.apache.commons.codec.language.Soundex().encode("Jonathan");
This is a simple test case that demonstrates the Soundex algorithm working correctly:
package com.mycompany; import static org.junit.Assert.assertEquals; import static org.junit.Assert.assertFalse; import static org.junit.Assert.assertTrue; import java.util.HashSet; import java.util.Set; import org.junit.Test; import org.swtk.common.framework.exception.BusinessException; import org.swtk.common.util.TextUtils; import org.swtk.eng.asm.svc.SoundexService; import org.swtk.eng.asm.svc.impl.SoundexServiceImpl; public final class SoundexServiceTest { @Test public void difference() throws Throwable { assertEquals(4, getService().difference("John Checker", "Jon Cecker")); assertEquals(4, getService().difference("John Checker", "John Checker")); assertEquals(2, getService().difference("John Checker", "John Doe")); assertEquals(1, getService().difference("John Checker", "Barack Obama")); assertEquals(4, getService().difference("Checker", "Cecker")); } @Test public void encode() throws Throwable { assertTrue(hasEqualEncoding("Jon Cecker", "John Checker", "J522")); assertTrue(hasEqualEncoding("Jon Smythe", "John Smith", "J525")); assertTrue(hasEqualEncoding("Jemima", "Jemimah", "Jemina", "JHEMIMAH", "Jhemimhah", "J550")); assertTrue(hasEqualEncoding("Jeremiah", "Jeremy", "J650")); /* what are the other *620's? */ assertEquals("C620", encode("Craig")); assertEquals("G620", encode("Greg")); assertEquals("T500", encode("Tim")); assertTrue(hasEqualEncoding("Trin", "Trinh", "Trim", "T650")); } private String encode(String value) throws Throwable { return getService().encode(value); } @Test(expected = BusinessException.class) public void encodeFailiures() throws Throwable { getService().encode("م"); } @Test public void equals() throws Throwable { assertTrue(getService().isEqual("Jon Cecker", "John Checker")); assertFalse(getService().isEqual("Barack Obama", "John Checker")); } private SoundexService getService() { return new SoundexServiceImpl(); } private boolean hasEqualEncoding(String... values) throws Throwable { Set<String> set = new HashSet<String>(); for (String value : values) { if (4 == value.length() && TextUtils.isNumeric(value.substring(1, value.length()))) set.add(value); else set.add(encode(value)); } return 1 == set.size(); } }
I loaded this data into MongoDB using the mongoOps.insert(...) command. Admittedly, this test hardly flexes the use case for Spring/Mongo; I expect that in the analysis stage. Insertion performance was tracked across 24 large files and 75 million records. ~50% of the names were non-English, and had to be discarded.
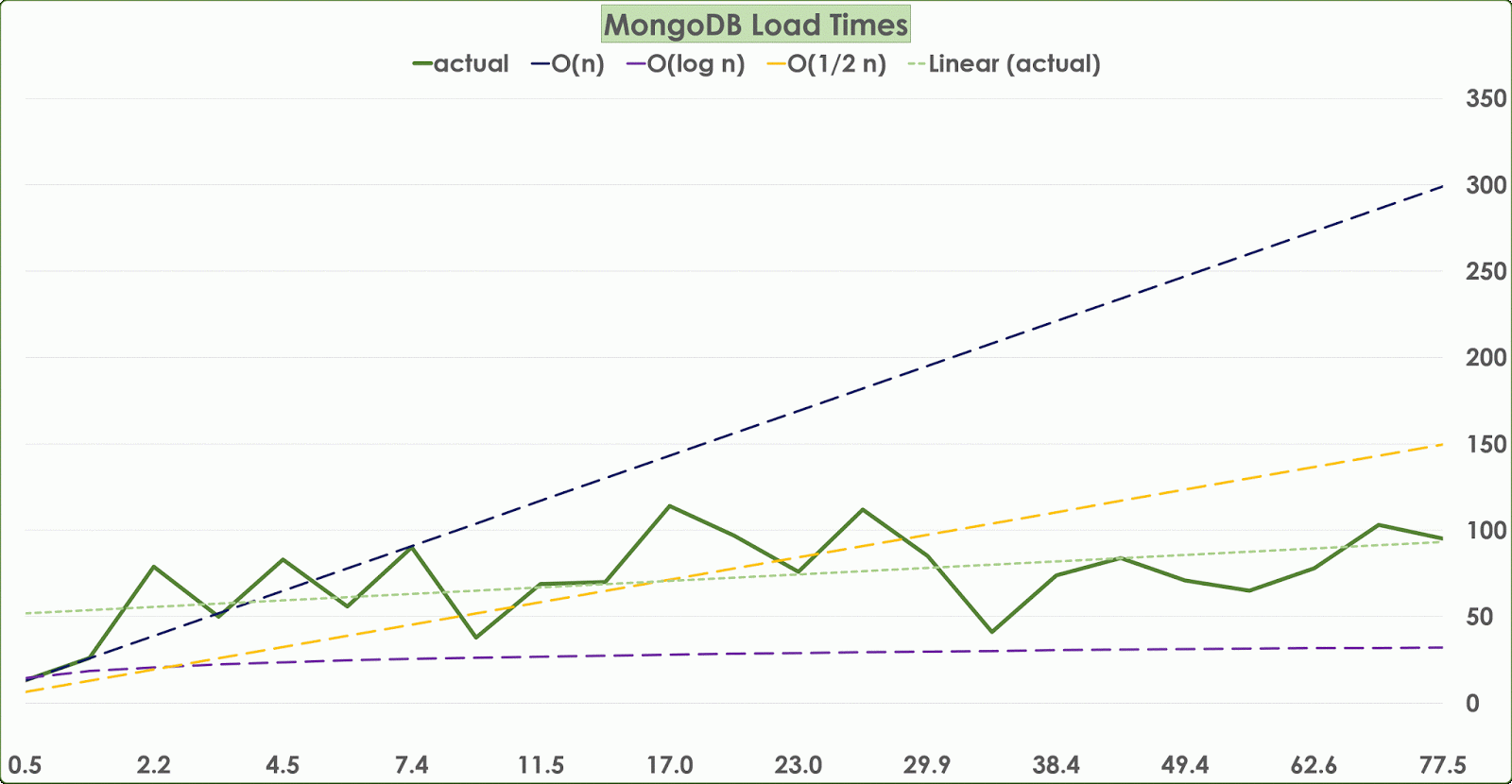
The x-axis represents the number of records being loaded (in millions). The y-axis represents the insertion time per record in milliseconds (ms). The jagged green line is the actual insertion performance on a ms-per-record basis. The lighter dotted green line is a linear trendline through the actual and seems to exhibit slightly better than O(1/2 n). For comparison, three hypothetical (dotted) lines are drawn. The blue line is O(n), the orange is O(1/2 n) and the purpose is O(log n).
The load performance is very reasonable. The total time to process the entire dataset (10 GB across a local LAN with gigabit ethernet and minimal computation prior to the db insertion, using a quad-core VirtuaBox image with 16GB ram for Ubuntu 14) was 19 minutes.
References
- Spring Reference Manual 1.6.1
- [Blog, Sept 2013] Spring Data and MongoDB: A Mismatch Made In Hell
- [Blog] The Soundex Algorithm
No comments:
Post a Comment